Une sélection de ressources (articles scientifiques, billets et autres liens) en lien avec les thématiques du DéSaN : entrepôts de données de santé, modèles de langage et, plus généralement, sciences de l’information dans le domaine de la santé. Ces ressources ont été repérées durant le mois d’avril 2025.
![]()
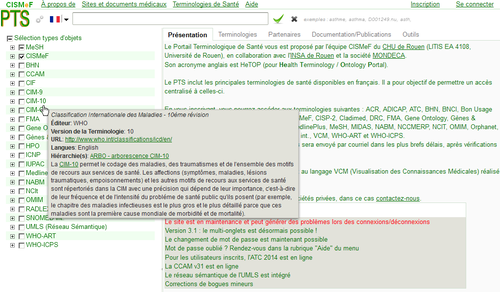
Cette veille existe également sous la forme de pages Wakelet et Zotero.
Thèmes Principaux et Idées Clés (réalisé avec Google NotebookLM) :
Veille scientifique DéSaN Avril 2025
1. Applications et Performances des LLM dans le Domaine Médical
- Question-Réponse Médicale et Diagnostic : Plusieurs études évaluent la capacité des LLM à répondre à des questions médicales et à aider au processus diagnostique.
- Le document « Goh_2025_natmed » indique que les médecins utilisant un LLM obtiennent de meilleurs scores que ceux utilisant uniquement des ressources conventionnelles pour les questions de décision de gestion (40,5 % contre 33,4 %), de décision diagnostique (56,8 % contre 45,8 %) et les questions spécifiques au contexte (42,4 % contre 34,9 %).
- Le document « liu_2025_crm » et « Sandmann_2025_natmed » font référence à des jeux de données de questions-réponses médicales, suggérant l’utilisation de ces ressources pour évaluer les LLM.
- Le document « Tordjman_2025_natmed » évalue la capacité de DeepSeek, un nouveau LLM, dans le domaine médical, en se concentrant sur la précision, les diagnostics différentiels et le raisonnement.
- Le document « mcduff_2025_nature » explore l’exactitude du diagnostic différentiel avec les LLM, comparant AMIE (un système assisté par LLM) à la recherche conventionnelle et aux cliniciens non assistés. Les résultats suggèrent qu’AMIE améliore l’inclusion du diagnostic final dans la liste de diagnostics différentiels.
- Le document « shan_2025_jmirmi » compare l’exactitude diagnostique des LLM et des professionnels cliniques dans diverses spécialités, montrant des résultats variables où les LLM peuvent surperformer ou sous-performer les cliniciens selon la spécialité et le contexte d’évaluation.
- Le document « tu_2025_nature » évalue les capacités de conversation et de raisonnement des LLM, cruciales pour les interactions cliniques, et suggère que les boucles d’auto-jeu améliorent la qualité des dialogues simulés.
- Extraction d’Informations : Les LLM sont évalués pour des tâches d’extraction d’informations à partir de textes biomédicaux.
- Le document « chen_2025_nc » examine différentes études évaluant les LLM dans des tâches extractives comme la reconnaissance d’entités nommées (NER) et l’extraction de relations. Il note que les approches de fine-tuning de pointe surpassent les LLM en mode « zero-shot » et « few-shot » dans la plupart des tâches BioNLP, en particulier pour l’extraction d’informations. Cependant, les LLM fermés comme GPT-3.5 et GPT-4 montrent de meilleures performances en mode « zero-shot » et « few-shot » dans les tâches liées au raisonnement, comme la réponse aux questions médicales.
- Le document « pan_2025_cibam » décrit l’utilisation de LLM pour l’inférence de maladies à partir de documents cliniques et l’extraction de paires clé-valeur pour les tests de laboratoire, permettant de comparer les résultats avec les directives cliniques pour le diagnostic de maladies comme le diabète ou l’hypertension.
- Extraction d’Événements Indésirables (ADE) : L’application des LLM à l’extraction d’informations sur les événements indésirables des médicaments est explorée.
- Le document « tanaka_2025_med » décrit une méthode basée sur les LLM pour extraire les paires médicament-ADE à partir des notices de médicaments de différentes régions (UE, Royaume-Uni, Japon), créant ainsi des bases de données supplémentaires pour étudier les ADE de manière exhaustive.
- Analyse de Documents Qualitatifs : Les LLM peuvent également être utilisés pour l’analyse de données qualitatives dans le domaine de la santé.
- Le document « player_2025_pm » présente un exemple de sortie d’un outil (DECOTA) utilisant des LLM pour l’analyse qualitative de données textuelles (concernant la défense contre les germes dans cet exemple), en identifiant des thèmes, des codes et des citations pertinentes.
- Modèles Spécifiques et Performances : Plusieurs LLM sont mentionnés et évalués dans les sources.
- GPT-3.5, GPT-4, GPT-4o, Llama 3 (8b, 70b), Llama 3.1 (405b), DeepSeek, DeepSeek-R1, DeepSeek-V3, Gemi2FTE, Med-PaLM, BERT, BART, LLaMA 2, et PMC LLaMA sont cités comme modèles utilisés et évalués.
- Le document « neves_2025_cibam » compare la prévalence de 20 affections chroniques identifiées par différentes stratégies de phénotypage, y compris plusieurs modèles LLM (GPT-3.5, GPT-4o, Llama 3 variants). Les performances de classification de ces modèles varient en fonction du niveau de confiance et du groupe d’âge des patients. GPT-4o semble avoir d’excellentes performances pour les niveaux de confiance moyen et élevé.
- Le document « chen_2025_nc » souligne que GPT-4 montre les meilleures performances globales, en particulier pour le raisonnement, mais est significativement plus coûteux que GPT-3.5. Les LLM open-source comme LLaMA 2 nécessitent souvent un fine-tuning pour atteindre des performances compétitives dans les applications BioNLP.
- Limitations et Améliorations Méthodologiques : Malgré leur potentiel, l’application des LLM en santé présente des défis méthodologiques.
- Le document « Kunze_2025_arthroscopy » souligne que les cas d’utilisation des LLM dans la recherche en soins de santé musculo-squelettiques sont redondants et manquent souvent de rigueur méthodologique appropriée. L’étude appelle à de meilleures pratiques méthodologiques pour l’intégration future des LLM dans la pratique clinique.
- Le document « ke_2025_npjdm » présente un nouveau cadre d’évaluation qualitative (S.C.O.R.E.) pour évaluer les réponses des LLM dans un contexte médical, se concentrant sur la sécurité, le consensus clinique, l’objectivité, la reproductibilité et l’explicabilité.
2. Gestion des Données de Santé et Confidentialité (CNIL)
Le déploiement accru du numérique en santé met en évidence l’importance cruciale de la sécurité et de la confidentialité des données des patients, en particulier dans les dossiers patients informatisés (DPI). Le document « CNIL_projet_de_recommandation_dossier_patient_informatise » fournit des recommandations détaillées sur la protection de ces données.
- Risques liés à la Cybersécurité : Les systèmes d’information de santé sont des cibles attrayantes pour les acteurs malveillants.
- Principes de Sécurité et de Confidentialité : La réglementation impose la mise en œuvre de mesures pour garantir la sécurité des données (confidentialité, intégrité, disponibilité) et la résilience des systèmes.
- Gouvernance et Habilitations : Une gouvernance stricte est nécessaire pour la gestion des accès au DPI.
- Données Collectées et Documents du DPI : Seules les données strictement nécessaires à la prise en charge et au suivi doivent être traitées.
- Conservation et Destruction des Données : Des règles spécifiques régissent la durée de conservation des dossiers médicaux et de leurs traces fonctionnelles/techniques.
- Réutilisation des Données : La réutilisation des données du DPI à des fins ultérieures (recherche, études, évaluation) est un traitement distinct.
- Partage et Échange d’Informations : Le code de la santé publique encadre l’échange et le partage d’informations entre professionnels impliqués dans la prise en charge d’une même personne, à condition que ces informations soient strictement nécessaires à la coordination ou à la continuité des soins.
3. Formation au Numérique en Santé
L’intégration croissante du numérique en santé nécessite une formation adéquate des futurs professionnels de santé.
- Le document « Bouraïma-Lelong_2025_rev-inf » mentionne le projet Satin à l’université de Caen, visant à former les étudiants en santé au numérique dans ce domaine. L’université de Caen Normandie, qui accueille un nombre important d’étudiants en santé, a développé ce projet dans le cadre de son UFR santé.